Hello !
Wow ça fait exactement 251 jours que je n’ai pas de partage avec vous le temps passe tellement vite, je suis désolé. Ces temps ci j’étais sur les codes, config de serveurs, tests, optimisations, … bref. Mais ne vous inquiétez j’ai des surprises pour vous alors stay tuned 😉
Avant de commencer je vais vous donner la définition de Web Scraping d’après Wikipédia :
Le web scraping (parfois appelé Harvesting) est une technique d’extraction du contenu de sites Web, via un script ou un programme, dans le but de le transformer pour permettre son utilisation dans un autre contexte.
La semaine passé j’ai remarqué que mon collègue regardait les parutions de gbitch à chaque fois qu’il avait du temps libre. Des fois il a du mal à le lire à cause d’une connexion qui n’est pas stable. Alors je lui ai proposé d’écrire un script pour extraire toutes les images en local 🙂 D’accord je vais vous montrer comment j’ai fait. C’est un tout petit script de rien du tout.
J’ai commencé par analyser la structure de la partie qui nous intéresse sur la page. Je vais vous faire une capture d’écran :

Comme vous pouvez le voir nous avons la liste des collections (des images) et une pagination. Ça c’est notre première page maintenant on regarde le code sources de la pagination pour voir si on peut extraire la liste des autres pages. Il suffit de faire un simple clic droit et inspecter le code :
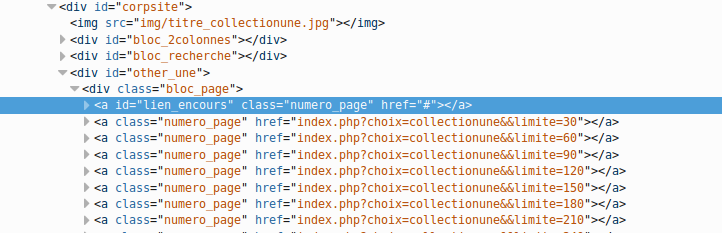
Voilà ! Les liens se trouvent sur une balise a.numero_page qui sont dans un bloc div#other_une donc on peut dire que le sélecteur CSS pour accéder à la liste des urls est : #other_une a.numero_page.
Maintenant on fait la même chose avec les images :
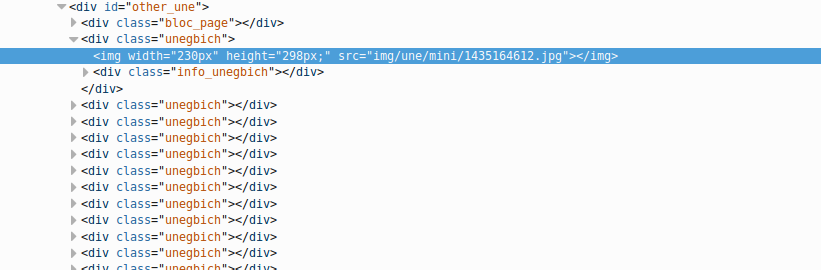
D’après le code source on peut dire que le sélecteur CSS pour accéder aux images est le suivant : .unegbich img.
C’est tout ce dont nous avons besoin pour extraire les URL des images. Maintenant passons au script.
Nous allons utiliser deux gems : rest_client qui va nous permettre de récupérer le code HTML d’une page web et la gem nokogiri qui est un parseur HTML et XML. Pour les installer il faut taper ces deux commandes (il faut mettre sudo devant si le système l’exige)
gem install rest_client
gem install nokogiri
première étape : récupération des URL des pages.
require 'nokogiri'
require 'rest_client'
base_url = "http://gbich.com/"
lien = "#{base_url}index.php?choix=collectionune&&limite=0"
html = RestClient.get(lien)
doc = Nokogiri::HTML(html)
pages = doc.css("#other_une a.numero_page")
pages.map! { |p| p['href'] }
puts pages
Nous avons récupérer le code HTML de la page avec RestClient.get(lien) puis le parser avec le code Nokogiri::HTML(html) et enfin récupérer la liste des urls des pages avec le sélecteur CSS doc.css("#other_une a.numero_page"). On obtiendra le résultat suivant après l’exécution du script :
#
index.php?choix=collectionune&&limite=30
index.php?choix=collectionune&&limite=60
index.php?choix=collectionune&&limite=90
index.php?choix=collectionune&&limite=120
index.php?choix=collectionune&&;limite=150
index.php?choix=collectionune&&;limite=180
index.php?choix=collectionune&&;limite=210
index.php?choix=collectionune&&;limite=240
index.php?choix=collectionune&&;limite=270
index.php?choix=collectionune&&;limite=300
index.php?choix=collectionune&&;limite=330
index.php?choix=collectionune&&;limite=360
#
index.php?choix=collectionune&&limite=30
index.php?choix=collectionune&&limite=60
index.php?choix=collectionune&&limite=90
index.php?choix=collectionune&&limite=120
index.php?choix=collectionune&&;limite=150
index.php?choix=collectionune&&;limite=180
index.php?choix=collectionune&&;limite=210
index.php?choix=collectionune&&;limite=240
index.php?choix=collectionune&&;limite=270
index.php?choix=collectionune&&;limite=300
index.php?choix=collectionune&&;limite=330
index.php?choix=collectionune&&;limite=360
Il a doublé urls, en fait il y a une pagination avant et après la liste des images c’est pourquoi on a ce résultat. Maintenant ce qu’on va faire c’est enlever l’ancre « # » de la liste et prendre la moitié du tableau puis mettre l’URL de base (http://gbich.com/) sur les liens et enfin ajouter le premier lien sur la liste. On ajoute ces 4 petites lignes :
pages -= ['#']
pages = pages[0..pages.size/2-1]
pages.map! { |p| base_url+p }
pages = ["http://gbich.com/index.php?choix=collectionune&&limite=0"] + pages
deuxième étape : récupération les URLs des images à extraire.
On ajoute ces lignes sur le script :
images = []
for page in pages
html = RestClient.get page
doc = Nokogiri::HTML(html)
for r in doc.css(".unegbich img")
images << base_url + r['src']
end
end
puts images
troisième étape (fin) : téléchargement des images 🙂
On va exécuter cette commande ruby script.rb > sortie_images.txt pour mettre la liste des URL des images sur un fichier sortie_images.txt.
Ensuite on utilise la commande wget pour télécharger les images. On crée un nouveau répertoire ensuite on se déplace dessus et exécuter la commande : wget -i sortie_images.txt et vous aurez les images en quelques secondes, minutes, heures, ... euh ça dépend de votre connexion internet 😛
Voilà c'est tout pour aujourd'hui, vous pouvez jeter un coup d'oeuil sur scrapy pour aller plus loin. Amusez vous bien 😉
Voici le script final :
require 'nokogiri'
require 'rest_client'
images = []
base_url = "http://gbich.com/"
lien = "http://gbich.com/index.php?choix=collectionune&&limite=0"
html = RestClient.get(lien)
doc = Nokogiri::HTML(html)
pages = doc.css("#other_une a.numero_page")
pages.map! { |p| p['href'] }
pages -= ['#']
pages = pages[0..pages.size/2-1]
pages.map! { |p| base_url+p }
pages = ["http://gbich.com/index.php?choix=collectionune&&limite=0"] + pages
for page in pages
html = RestClient.get page
doc = Nokogiri::HTML(html)
for r in doc.css(".unegbich img")
images << base_url + r['src']
end
end
puts images